
![7 Best AI Coding Assistants In 2023 [Free + Paid]](jpg/16952882603blllo1oza.jpg)
![30 Cool, Easy & Fun Python Projects + Source Code [2023]](png/1655865129yuz5v1mdab.png)

![The 14 Best TensorFlow Courses in 2023 [Free + Paid]](png/1624550510xonrryd0t0.png)
![10 Best Design Books for Design Students [Updated]](png/1642872008wcnbdsvf6q.png)
![I Ranked the Top 5 Best AI Image Generators [with Image Examples]](jpg/1682848644stltm9ynp6.jpg)




What is Streaming?

Source: Spark.apache.org
Streaming is the act of processing data as quickly as possible. So quick that it might seem like it's being done in real-time.
In 2017, IBM's Directory of Research, Arvind Krishna, gave a speech. He declared that streamed data loses value in milliseconds if it is not captured and analyzed more-or-less instantly.
Today, the streaming industry is worth around $125 billion, so failure to quickly capture and process real-time data can lead to billions of dollars worth of losses.
The streaming industry isn't valuable only to commerce. It is also valuable in all sorts of other human activities. For example, law enforcement agencies could use real-time data to keep tabs on suspects. Security services could analyze international passenger travel on the fly, looking for patterns that might highlight suspicious behavior. Films and music can be shared by millions of people instantaneously.
In short, we care about streaming because if we don't, we might lose billions of dollars a year or lose many opportunities to work and play more efficiently.
Streaming and Big Data
It will always be easier to process small amounts of data in real-time rather than large amounts. This becomes even more obvious when we speak of Big Data, which involves data of massive proportions.
Big Data projects involve vast amounts of information that computer systems distinguish between data at rest and in motion. 'Data at rest' is data physically stored on a device, and 'data in motion is data moving between storage devices.

Source: Wikipedia.org
Streaming vs Batch Processing
'Streaming' means transmitting and processing data in real-time. Information is processed at nearly the same rate as it is produced.
Data scientists and software engineers distinguish streaming from batch processing. In batch processing, something produces data in chunks, and later, one or more 'somethings' process those chunks. As we will see later when we discuss Spark Streaming, this distinction can be significant.
When artificial intelligence (AI) instantly responds to stock market movements, it is doing streaming. On the other hand, when a computer server sends sales data from several regions to the company's headquarters for out-of-hours processing, it does batch processing.
Note: Streaming deals with data in motion, while batch processing deals with data at rest.
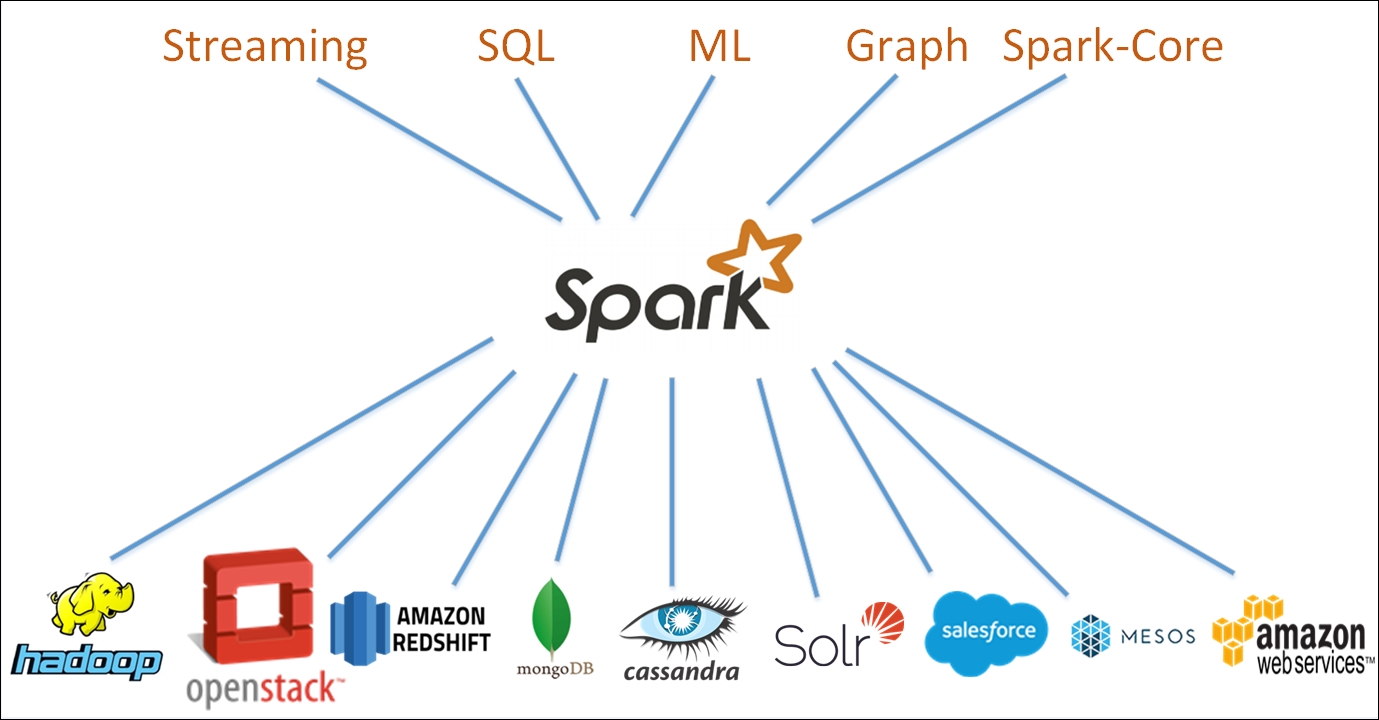
An Introduction to Apache Spark
The Apache Spark Engine
Apache Spark (or just Spark) is an open-source computing engine. The Spark engine works hand-in-hand with separate code libraries as an integrated system. The system handles humongous amounts of data by using parallel processing across computer clusters.
Spark is the industry-standard tool for data scientists and developers interested in streaming big data.
Note: If you are familiar with streaming big data, note that Spark is not a revised version of Hadoop.

What is Spark Streaming?
Source: Packtpub
Spark Streaming (or, properly speaking, 'Apache Spark Streaming') is a software system for processing streams. Spark Streaming analyses streams in real-time.
In reality, no system currently processes streams in genuine real-time. There is always a delay because data arrives in portions that analytical engines can consume.
How Does Spark Streaming Work?
In a nutshell: Apache Spark Streaming (or just Spark Streaming) uses the Spark engine to analyze big data streams.
Spark Streaming processes streams in near real-time using parallel data processing. Spark Streaming does its parallel processing on several computer clusters simultaneously.
Data Engineering using Kafka and Spark Structured Streaming
Parallel Data Processing
In the early days of computing, long-running tasks had to share a single processor. To fix this problem, software engineers the processor to “pay attention” to each task in separate channels called threads. It is the basis of computer 'multithreading.’ Multithreading gave computer users the pretense that their machines could do several things simultaneously.
As computer technology improved, it became possible to really share tasks across multiple separate processors. Computers were no longer faking it. They were now doing parallel processing.
Example: Imagine cooking a large meal on a one-ring cooker. You'd swap pots and pans as needed. It is like multithreading. Now imagine cooking that same meal on a multi-ring cooker. All the pots and pans could be heated at the same time. It is like parallel processing.
The Apache Spark engine handles all the problems of coordinating parallel data processing across multiple computer clusters.
Computer Clusters
Networked computers branch out from intersections called nodes. Each node is a physical device that carries out the same task as other nodes. A master machine or 'controller' assigns tasks to nodes. We call computers cooperating in tandem in this way, computer clusters.
Spark Streaming gets its immense power and flexibility from being able to do parallel processing on computer clusters.

Advantages of Spark
Spark supports a wide range of programming languages. Therefore, Spark is highly flexible programmers from many different backgrounds can use it. Spark supports Java, Python, R, Scala, and SQL.
Because of its satellite code libraries, Spark has a wide range of tasks, from streaming to machine learning to data storage and handling.
Spark is highly scalable. Users can work with Spark on a single laptop, a small company network, or on a massive network of computer clusters that scales across several countries.
More advantages include:
- Spark does fast large-scale data processing.
- It supports several types of computer tasks.
- Spark reads and writes to Hadoop (properly, Apache Hadoop) systems.
- Spark is more efficient than its main rival, MapReduce.
- Spark beats MapReduce at running complex calculations on data-at-rest sources.
- Many see Spark as the natural successor to MapReduce.
- Spark is up to 40 times faster than Hadoop.
- Spark can consume data from several sources.
- Spark can push results to databases, file systems, and live dashboards. Users can even configure many other output destinations.
Apache Spark: High-Level Design Details
This section is a birds-eye view of Spark's internal design. It is a bit more technical than the rest of this article. Still, it is an essential read for anyone who wants to understand the Spark ecosystem.

Spark's main bits and pieces occupy three distinct levels: the components level, the core level, and the frameworks level.
The Components Level
Four components sit at this level:
- Spark SQL Structured data.
This component enables users to query organized data. - Spark Streaming real-time.
This component enables users to process live data streams. It is the component that provides real-time analytics. - MLLib machine learning.
MLLib (Machine Learning Library) is the component that offers users numerous machine learning algorithms. - GraphX graph processing.
This component is Spark's native tool for doing graphical calculations.
The Spark Core Level
The Spark core component level handles all the basic functionality that Spark makes available to users. It includes–but is not limited to–fault recovery, memory management, storage systems interactions, and task scheduling.
The Frameworks Level
Standalone Scheduler
This framework works at the cluster level to bring together all the resources needed by multiple Spark applications. In doing this, the framework reduces duplication of effort and helps to ensure redundancy.
(Redundancy helps ensure that a single point of failure will not bring down the entire system.)
The master process in Spark uses this framework to manage its clusters and regulate resources across all those clusters.
YARN (Yet Another Resource Allocator)
The easy way to think about YARN is that it provides applications to manage the computing resources they use. Because of YARN, applications can manage even resources spread across many machines or many computer clusters.
Advanced readers can think of YARN as a cluster-level operating system that provides a resource-management framework.
Mesos
Mesos is open-source software for managing computer clusters. Mesos is specially designed to operate in widely spread out computer environments. It is centralized and highly fault-tolerant.
How to Visualize Spark's Architecture
In your mind's eye, imagine that the components level is the top layer, the core level is the middle layer, and the framework level is the bottom layer. Relative positions don't indicate anything special, though. The main thing to take away here is that the core layer is central to everything in Spark.
Streaming Faults and How They Affect Spark?
No system is 100% foolproof. Every so often, something goes wrong. In streaming, packets of data can mysteriously go missing, never to be heard from again. Other packets show up late, like stragglers to a party. In fact, in computer science, these packets really are called 'stragglers.’ They are out of sync with what came before and what will come after. Sometimes, hardware malfunctions also cause problems.
Regardless of the reason, streaming faults cannot be allowed in a sensitive environment. Bank transactions must be faithfully recorded. Airline tickets that have been sold must be assigned to the correct passenger.
Stream processors can recover faults, but it is an expensive business, both time and money.
Recovery involves long restoration times and 'hot' replication. (Hot replication means doing replication while the system is still dealing with live data.) Streaming processing systems do not usually handle stragglers efficiently.
Spark has evolved two strategies to deal with faults, DStreams and Dataframes. Both have their pros and cons.
How Spark Streaming Deals with Faults
Spark Streaming uses discretized streams (DStreams) to achieve fault-tolerant streaming. DStreams is a way of recovering from faults with a better track record than traditional replication and backup methods. DStream also tolerates stragglers.
How Spark Structured Streaming Deals with Faults
Spark Structured Streaming uses a continuous streaming method that enables the system to handle streaming data continuously. It avoids many problems with handling faults and stragglers because Structured Streaming waits for all the data to arrive before updating the final result.
Spark Structured Streaming uses DataFrames.
Spark Streaming vs. Structured Streaming
Spark Streaming's DStreams are made up of sequential RDD (Resilient Distributed Dataset) blocks. Although fault-tolerant, DStream analysis and stream processing is slower than its DataFrames competitor. It means that DStreams are less reliable in delivering messages compared to Dataframes.
Structured Streaming uses DataFrames for analyzing and processing data. It can do this because it is built directly on the Apache Spark engine.
Of the two interfaces, Spark Structured Streaming is better for skilled software developers who have plenty of experience working with distributed systems.
Well-Known Spark Users
Here, we provide two use-cases of 'serious' Spark users. We trust that by so doing, you will get a firm idea of where Apache Spark sits in the modern big data universe.
Yelp
Yelp uses Apache Spark to predict the likelihood that a given user will interact with a particular advertisement. By doing this, Yelp has increased the number of people clicking on its advertising and, therefore, its revenue.
Yelp used Apache Spark to process the enormous amounts of data needed to train machine-learning algorithms to reliably predict human behavior.
Hearst
Hearst Corporation is a vast, diversified information and media company that offers its customers viewable content from over 200 websites. Hearst's editorial team can monitor which articles are doing well and which hot topics by using Apache Spark Streaming via Amazon EMR.
Conclusion
Apache Spark Streaming is a powerful tool for writing streaming applications that operate on big data. Spark Streaming is on course to overtake its main rival, Map Reduce, as the leading big data streaming processor reasonably soon. Data scientists and developers who can choose to work with either are likely to be better served to concentrate on Spark Streaming.
The Spark engine offers users a choice of two streaming-processing models: Spark Streaming and Spark Structured Streaming. Although fault-tolerant, Spark Streaming can struggle with handling stragglers (see "How Spark Streaming deals with streaming faults" above).
Spark Structured Streaming is not only fault-tolerant. It also handles stragglers without difficulty due to the way it is designed. Even better, using Structured Streaming, it only takes a few code changes to easily make the job work with your other data processing applications. However, the downside is that Spark Structured Streaming is more challenging to work with than Spark Streaming.
People are also reading:
- Top Spark Interview Questions and Answers
- Difference between Hadoop vs Apache
- Top-Rated Apache Spark Courses
- What is Hadoop?
- Hadoop Ecosystem Components
- What is Hadoop Architecture?
- Top Data Science Interview Questions & Answers
- Data Science Python Libraries
- What is Data-Science?
- Best Data-Science Books
